728x90
반응형
SELECT
COUNT(1) AS CNT_1
, COUNT(*) AS CNT_ASTERISK
, COUNT(SEQ) AS CNT_NULL
, COUNT(CL_UNI_CD) AS CNT_DATA
, COUNT(DISTINCT CL_UNI_CD) AS CNT_DISTINCT
FROM COM_CD;[출력 결과]

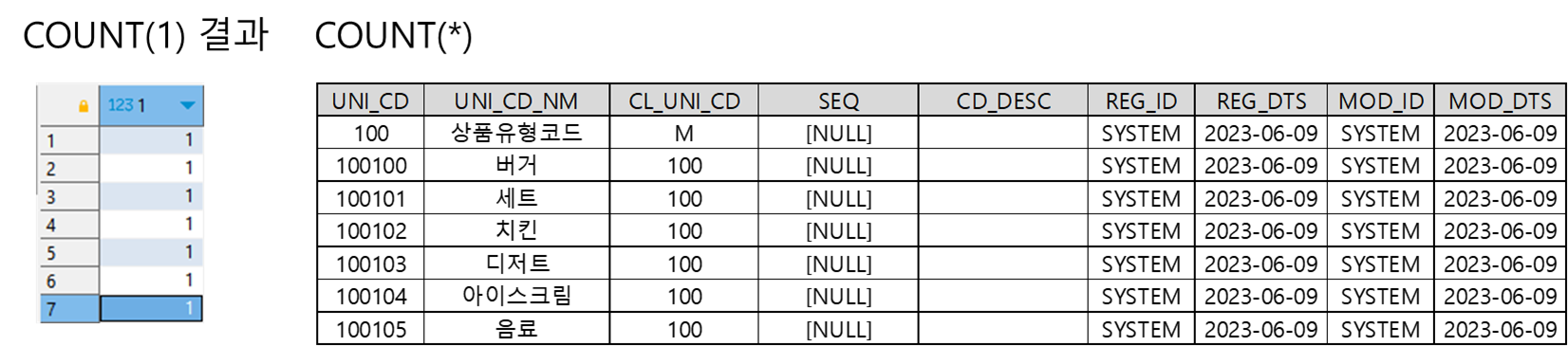
1. COUNT(1), COUNT(*)의 차이
count(1)과 count(*)은 테이블 전체의 행의 개수를 확인하기 위해서 사용
결론적으로는 큰 차이는 없다. 아래 데이터 검증 결과에서 알 수 있듯이, count(*)은 테이블의 모든 행을 세고,
count(1)은 결과 행을 세는데 사용되는 상수 1을 count한다.
COUNT(*), COUNT(1) 둘 다 행의 NULL 값이 있더라도 행의 전체 개수를 반환함.
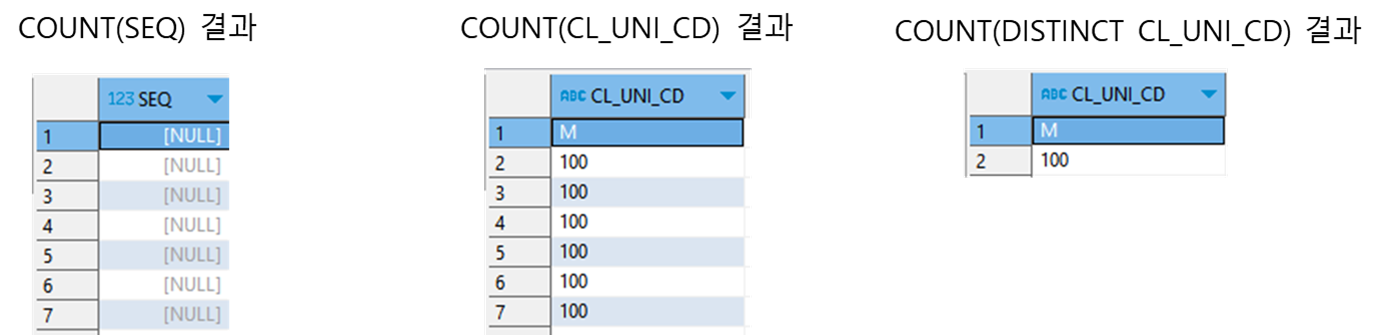
2. COUNT(col), COUNT(DISTINCT col)
- count(col)의 경우 null 값을 제외한 rows를 확인하기 위해서 사용함.
만약 해당 컬럼이 모두 null인 경우 0의 값을 return 함. - count(DISTINCT col)의 경우 중복값을 제외한 unique한 개수를 알기 위해서 사용함
728x90
반응형
'Study > SQL' 카테고리의 다른 글
| [PostgreSQL] Permission denied Error (0) | 2023.07.13 |
|---|---|
| [MySQL] JOIN조건과 WHERE조건의 차이 (0) | 2023.06.23 |
| [MySQL] GROUP BY 와 DISTINCT의 차이 (0) | 2023.06.22 |
| [SQL] 2장 인덱스 기본 (0) | 2023.06.05 |
| [SQL] 1장 SQL 처리 과정과 I/O (1) | 2023.06.02 |


