728x90
반응형
빅데이터, 데이터 엔지니어에 대해 검색하다보면 Date Mart(데이터 마트, DM), Data Warehouse(데이터 웨어하우스, DW), Data Lake(데이터 레이크, DL) 등의 단어를 쉽지 않게 볼 수 있다.
데이터 레이크
-. 원시 데이터 및 비정형 데이터의 중앙 리포지토리
-. 먼저 데이터를 저장하고 나중에 처리할 수 있음
데이터 웨어하우스
-. 데이터를 구조화된 형식으로 저장
-. 분석 및 비즈니스 인텔리전스를 위한 사전 처리된 데이터의 중앙 리포지토리
데이터 마트
-. 회사의 금융, 마케팅 또는 영업 부서와 같은 특정 사업부의 요구 사항을 지원하는 데이터 웨어하우스

1. 데이터 레이크(Data Lake)
1-1. Data Lake의 개념
"If you think of a datamart as a store of bottled water – cleansed and packaged and structured for easy consumption – the data lake is a large body of water in a more natural state."
"깨끗이 처리되고, 포장되며, 사용하기 쉽도록 구조화된 생수병 저장고"로 생각한다면, 데이터 레이크는 "더욱 자연스러운 상태의 큰 물모양"
- 2010년 미국 비즈니스 인텔리전스 기업인 펜타호 공동창업자인 제임스 딕슨이 소개한 데이터 레이크 -
- Data Lake는 다양한 소스에서 생성된 대규모의 원시 데이터(Raw data)를 저장하고 관리하기 위한 시스템
- 데이터 형식에 상관없이 모든 데이터를 원래의 형식 그대로 저장(*정형·반정형·비정형 데이터)
- 이후 필요에 따라 데이터를 추출(Extract)하고 변환(Transfrom)
정형 데이터
-. 엄격하게 정의된 데이터 타입과 포맷을 가진 데이터를 의미
-. 일반적으로 데이터베이스의 열과 행으로 표시되는 테이블 형식 데이터
-. RDMS
반정형 데이터
-. 데이터의 구조 정보를 데이터와 함께 제공하는 파일 형식의 데이터
-. XML, HTML, JSON
비정형 데이터
-. 정의된 구조가 없는 정형화되지 않은 데이터
-. 동영상 파일, 오디오 파일, 사진, 보고서, 메일 본문
1-2. Data Lake의 구조 및 특징
- Data Lake에서는 데이터를 저장하기 전 정제를 하지 않는다.
- 정형·반정형·비정형 데이터를 저장할 수 있다.
- 미리 정의된 목적이 없는 데이터를 저장
- 즉시 데이터를 수집할 수 있다.
- 주로 Data Scientist가 주로 이용
1-3. 아키텍처(Architecture)
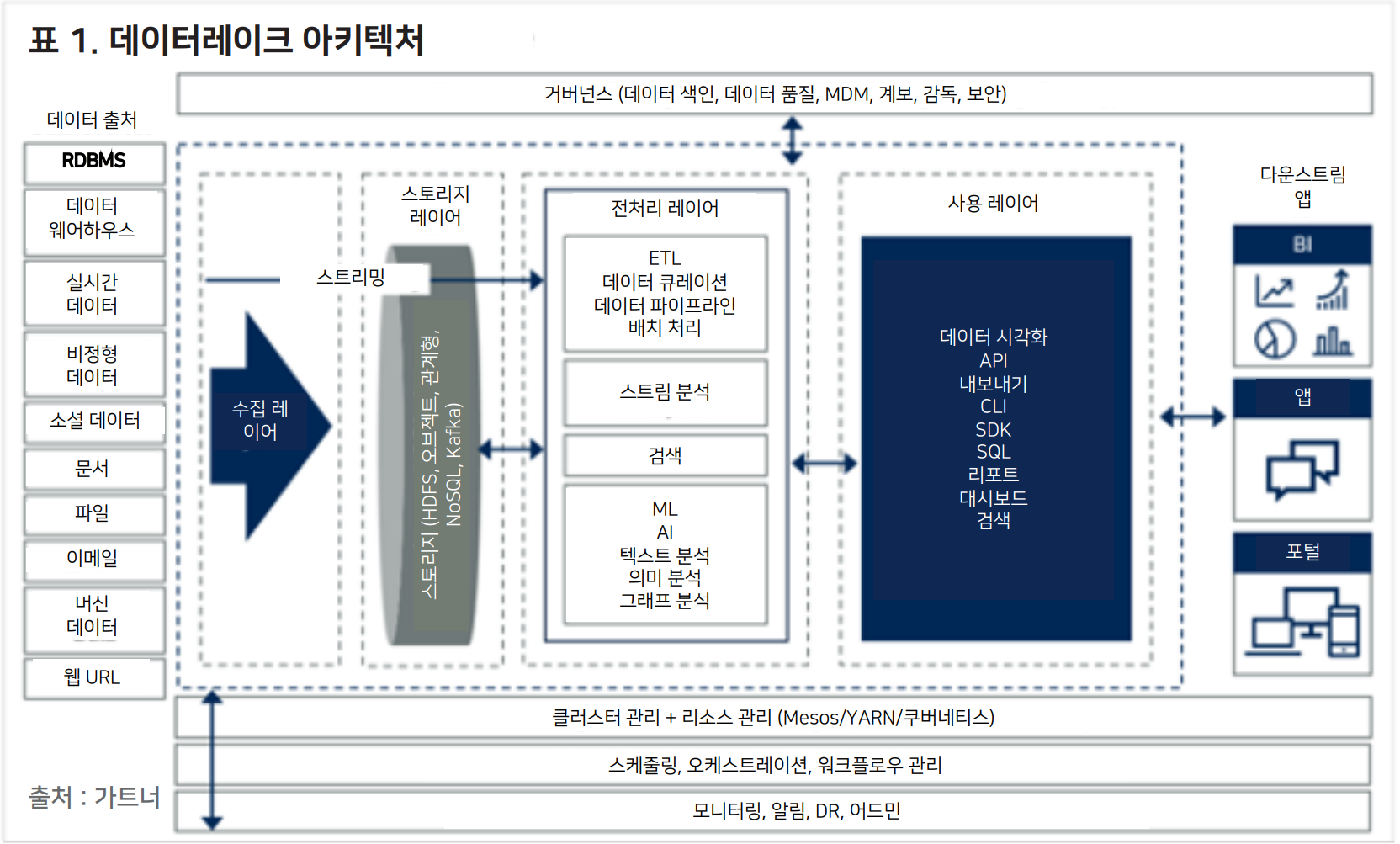

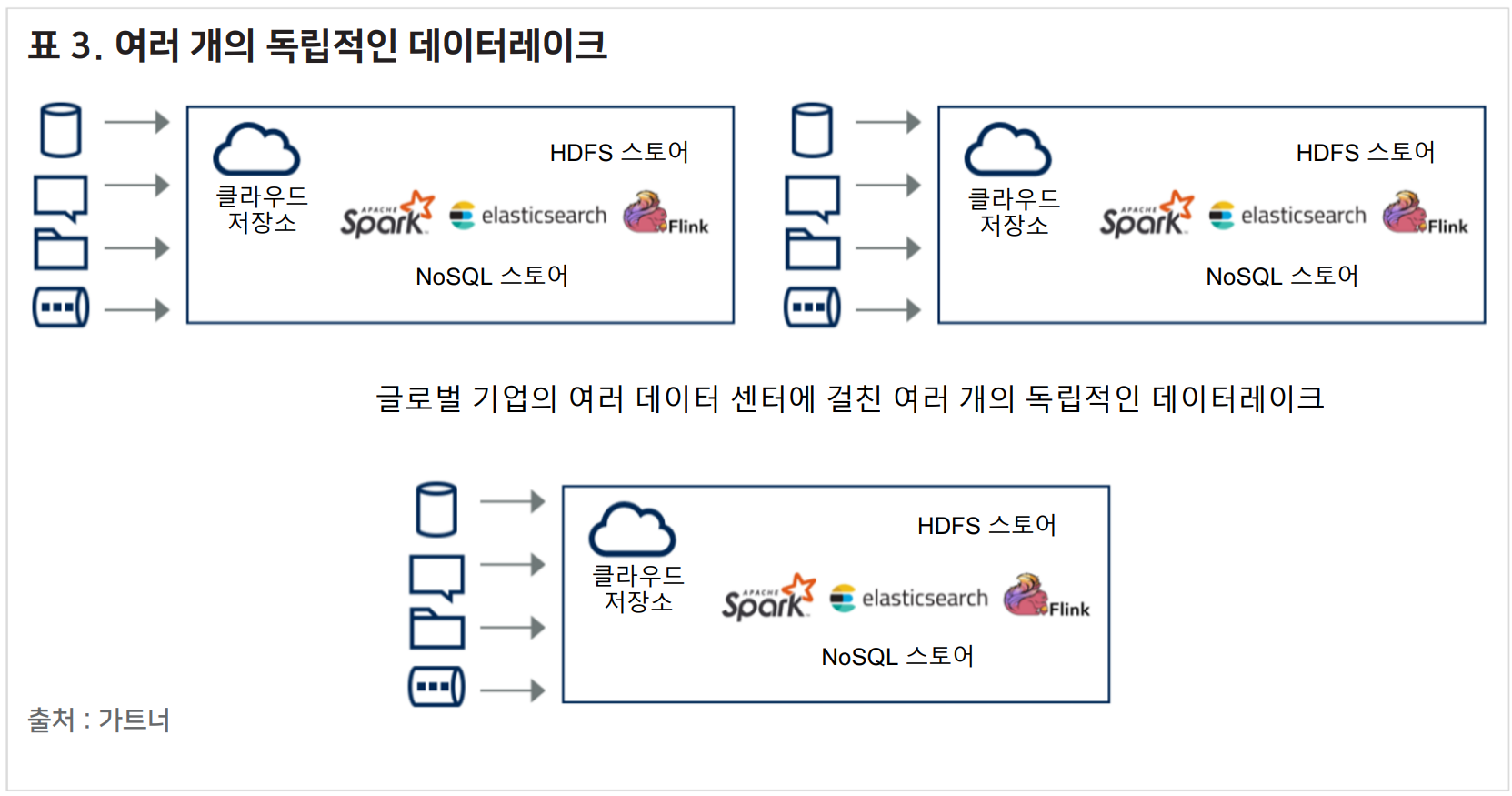
1-4. 스토리지(Stroge)
- NoSQL 데이터 스토리지(Cassandre, MongoDB)
- 관계형 데이터 스토리지(MySQL. MS SQL, PostgreSQL ..)
- 스트리밍 메세지/이벤트 스토리지(Kafka, rabbitMQ)
- New SQL 데이터 스토리지
- 인메모리 데이터 스토리지(SPARK)
- 분산 파일 시스템(HDFS)
- 오브젝트 데이터 스토리지
[요약]
| 데이터레이크 | |
| 개념 | 원시 데이터를 그대로 저장하는 대규모 데이터 저장소 |
| 데이터 형태 | 정형, 비정형, 반정형 데이터 |
| 주 사용 목적 | 다양한 데이터 분석과 머신러닝 |
| 구축과 관리의 복잡성 | 상대적으로 높음(데이터 관리 필요) |
| 활용 사례 | 빅데이터 분석, 실시간 분석, 머신러닝 등 |
| 주요 장점 | 유형에 관계없는 대량의 데이터 자장 및 분석 가능 |
| 주요 단점 | 데이터 품질 관리와 카탈로그화 필요, "데이터 스와프 위험" |
데이터 스와프
데이터레이크에서 관리되지 않는 데이터가 쌓이는 현상을 의미합니다. "스와프"라는 단어는 늪이나 물에 뒤덮인 토지를 의미하는데, 이것이 데이터레이크에 비유되어 사용되고 있습니다. 데이터레이크는 원시 데이터를 그대로 저장하므로, 어떤 데이터가 어디에 있는지, 어떤 형태로 저장되어 있는지, 어떻게 사용되어야 하는지 등을 트래킹하지 않으면, 그 데이터는 찾기 힘든 '데이터 스와프'에 빠질 수 있습니다.
데이터 스와프는 데이터의 가치를 감소시키며, 분석이나 의사결정에 필요한 정보를 찾는 데 시간과 노력을 낭비하게 만듭니다. 이를 방지하기 위해서는, 데이터 거버넌스와 메타데이터 관리가 중요합니다. 데이터를 잘 정리하고 분류하며, 어떤 데이터가 어디에 저장되어 있는지, 어떤 형태로 저장되어 있는지 등의 정보를 메타데이터로 관리하면, 데이터 스와프 문제를 피할 수 있습니다.
따라서, 데이터레이크를 구축하고 운영하는 데 있어, 데이터의 품질을 유지하고 데이터 카탈로그를 구축하며, 적절한 데이터 거버넌스를 실시하는 것이 중요합니다.
참고사이트
https://www.samsungsds.com/kr/insights/big_data_lake.html
https://www.bespinglobal.com/pardot/200410_mkt_package/mkt_bigdata.pdf
https://aws.amazon.com/ko/compare/the-difference-between-a-data-warehouse-data-lake-and-data-mart/
728x90
반응형