하둡은 기본적으로 HDFS, MapReduce로 구성되어 있다. 맵릳듀스는 HDFS에 저장된 파일을 분산 배치 분석을 할 수 있게 도와주는 프레임워크 이다. 따라서, 개발자는 맵리듀스 프로그래밍 모델에 맞게 Map, Reduce를 구현해야 한다. 개발자는 key / value 쌍을 처리하는 Map 함수를 설정하여 중간 결과물 형태의 Key / value 쌍 데이터를 만들고, Reduce 함수를 설정하여 Map 함수의 중간 결과물의 Key를 가진 값들을 합쳐서 최종 결과물을 만든다.
1. MapReduce의 구성
하둡에서 수행하는 역할은 크게 HDFS에서 파일을 저장과 데이터를 처리하는 맵리듀스로 역할로 나누어 진다. 기본적으로 Master-Slave 구조를 가지고 있다. 그리고 아래의 그림과 같이 Layer가 나뉘어 설계 되어 있다. HDFS의 NameNode와, MapReduce의 JobTracker, HDFS의 DataNode와 MapReduce의 TaskTracker는 비슷한 역할을 수행한다고 볼 수 있다.

| 프레임워크 | 컴포넌트 | 설명 |
| HDFS | NameNode | 파일 시스템의 메타데이터 관리 |
| HDFS | DataNode | 실제 데이터 블록을 저장 |
| MapReduce | JobTracker | 모든 Map, Reduce 작업 스케줄링 관리 |
| MapReduce | TaskTracker | 실제 Map, Reduce 작업 수행 |
2. MapReduce의 처리 과정
2-1. 기본 구조
- Map Phase : 입력 데이터를 key-value 쌍으로 분리하고 중간 결과를 생성
- Reduce phase : 중간 결과의 key에 따라 value들을 그룹화 하고, 그룹별로 원하는 연산을 수행하여 최종 결과를 생성
2-2. Word Count 예시
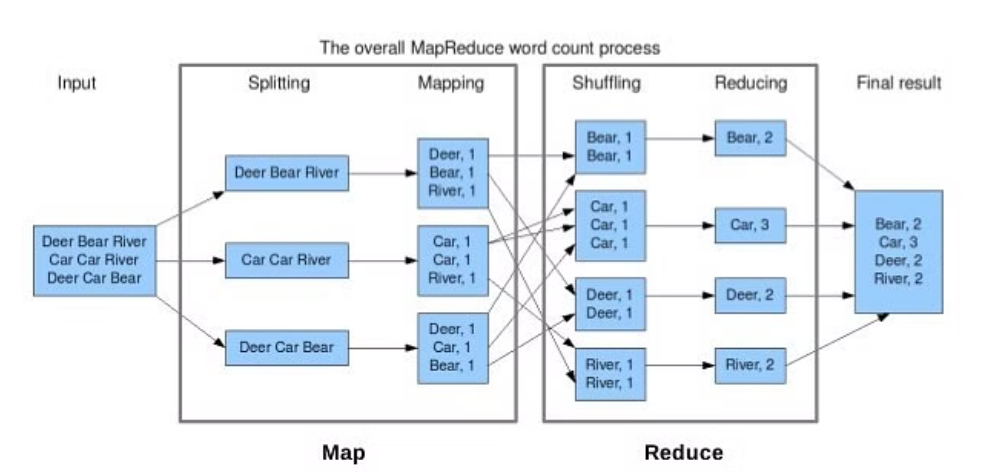
- 단어의 개수를 세기 위한 텍스트 파일들을 HDFS에 업로드 하고, 각각의 파일은 Block 단위로 나누어 저장된다.
- 순차적으로 Block을 입력받는데, Splitting 과정을 통해 Block 안의 텍스트 파일을 한 줄로 분할한다.
- Map 연산을 통해 (Word, 1) 과 같이 반환한다.
- Shuffling 과정을 통해 연관성 있는 데이터끼리 모아 정렬한다.
- Reduce(Word, 개수)를 수행하여 각 Blcok에서 특정 단어가 몇번 나왔는지 계산한다.
- 이후 결과는 합산 후 HDFS에 파일로 결과를 저장한다.
2-3. Python으로 MapReduce 구현
def spliter(data):
return data.split('\n')
def mapper(sentence):
return [(word, 1) for word in sentence.split()]
def shuffle(map_result):
temp = {}
for map_data in map_result:
for k, v in map_data:
temp[k] = temp.get(k, []) + [v]
return temp
def reducer(shuffle_result):
return {k : sum(v) for k, v in shuffle_result.items()}
def sorting(reduce_result):
return dict(sorted(res.items(), key=lambda x: x[1], reverse=True))
결과
입력 데이터 :
Deer Bear River
Car Car River
Deer Car Bear
--------------------------------------------------
spliter 결과 :
['Deer Bear River', 'Car Car River', 'Deer Car Bear']
--------------------------------------------------
mapper 실행
입력 데이터 :
Deer Bear River
--------------------------------------------------
mapper 결과 :
[('Deer', 1), ('Bear', 1), ('River', 1)]
--------------------------------------------------
mapper 실행
입력 데이터 :
Car Car River
--------------------------------------------------
mapper 결과 :
[('Car', 1), ('Car', 1), ('River', 1)]
--------------------------------------------------
mapper 실행
입력 데이터 :
Deer Car Bear
--------------------------------------------------
mapper 결과 :
[('Deer', 1), ('Car', 1), ('Bear', 1)]
--------------------------------------------------
shuffle 실행
입력 데이터 :
[[('Deer', 1), ('Bear', 1), ('River', 1)], [('Car', 1), ('Car', 1), ('River', 1)], [('Deer', 1), ('Car', 1),
('Bear', 1)]]
--------------------------------------------------
shuffle 결과 :
{'Deer': [1, 1], 'Bear': [1, 1], 'River': [1, 1], 'Car': [1, 1, 1]}
--------------------------------------------------
reducer 실행
입력 데이터 :
{'Deer': [1, 1], 'Bear': [1, 1], 'River': [1, 1], 'Car': [1, 1, 1]}
--------------------------------------------------
reducer 결과 :
{'Deer': 2, 'Bear': 2, 'River': 2, 'Car': 3}
--------------------------------------------------
sorting 실행
입력 데이터 :
{'Deer': 2, 'Bear': 2, 'River': 2, 'Car': 3}
--------------------------------------------------
sorting 결과 :
{'Car': 3, 'Deer': 2, 'Bear': 2, 'River': 2}
--------------------------------------------------
{'Car': 3, 'Deer': 2, 'Bear': 2, 'River': 2}3. MapReduce의 한계
3-1. 복잡한 셔플링
Map과 Reduce 과정은 상당히 단순하지만, 이 둘 사이를 연결해주는 Shuffling 과정이 복잡하며 속도 또한 느린 것으로 악명이 높다고 한다. 그래서 하둡 엔지니어들 사이에서는 MapReduce를 small Map, large Shuffle, small Reduce라고 불러야 한다는 농담이 있다고 한다.
3-2. 잦은 파일 I/O
각각의 노드들은 map이나 reduce 작업을 하기 위해서 파일을 읽고 쓰는 작업을 합니다. Mapper는 분산 파일 시스템에서 데이터를 읽어와서 중간 key / value를 생성한 뒤, 자신의 디스크 공간에 파일을 씁니다. Reducer는 다시 이 파일을 읽어와서 리듀스 작업을 진행한 다음 결과 파일을 분산 파일 시스템에 출력합니다. 이렇게 반복적인 disk I/O는 성능 저하의 원인이 되며, 추후 spark가 이러한 문제점을 해결하기 위해 메모리 단에서 연산을 수행하는 방식을 제안합니다.
참고
(1) https://mangkyu.tistory.com/129
(2) https://www.projectpro.io/hadoop-tutorial/hadoop-mapreduce-tutorial-
(3) https://cloud.google.com/blog/products/bigquery/in-memory-query-execution-in-google-bigquery?hl=en
(4) https://kadensungbincho.tistory.com/112