프로젝트의 목표는 Docker 를 활용하여 카프카로 데이터를 수집하고 RDB에 저장하는 것이 1차 목표이다.
Docker를 사용해 본적이 없었기 때문에 생활코딩(이고잉)님의 Docker 입문 수업을 듣고 시작하였다. 제목에서 처럼 Docker에 대해서 1도 몰랐더라도 비유적으로 설명을 잘 해주시기 때문에 이해는 금방 잘 되었던 것 같다.
그리고, 이 프로젝트를 하면서 가장 고민을 많이 했었던 부분은 어떤 데이터를 수집을 할 것인가가 가장 오랫동안 고민을 했었던 것 같다. 긴 고민 끝에 선택한 건 네이터 증권 *테마주식 데이터를 수집하는 것으로 결정하였다.
* 테마주식 : 특정한 이슈나 사건, 경제적 변화 등에 관련되어 주목받는 주식
증권 테마주식 데이터를 보면, 예를 들어, 삼성전자 종목이 있다고 하면, 삼성전자는 어떤 테마주에 속해 있을까?
| 종목명 | 시장구분 | 테마명 |
| 삼성전자 | 코스피 | 무선충전기술 |
| 삼성전자 | 코스피 | 가상현실(VR) |
| 삼성전자 | 코스피 | 삼성페이 |
| 삼성전자 | 코스피 | NFT(대체불가토큰) |
| 삼성전자 | 코스피 | 스마트홈(홈네트워크) |
| 삼성전자 | 코스피 | 스마트폰 |
| 삼성전자 | 코스피 | LED |
| 삼성전자 | 코스피 | 아이폰 |
| 삼성전자 | 코스피 | 플렉서블 디스플레이 |
| 삼성전자 | 코스피 | IT 대표주 |
| 삼성전자 | 코스피 | OLED(유기 발광 다이오드) |
| 삼성전자 | 코스피 | 제습기 |
| 삼성전자 | 코스피 | 태블릿PC |
| 삼성전자 | 코스피 | 폴더블폰 |
| 삼성전자 | 코스피 | 자율주행차 |
| 삼성전자 | 코스피 | 자율주행차 |
| 삼성전자 | 코스피 | 공기청정기 |
| 삼성전자 | 코스피 | 마이크로 LED |
| 삼성전자 | 코스피 | 갤럭시 부품주 |
| 삼성전자 | 코스피 | RFID(NFC 등) |
| 삼성전자 | 코스피 | 4차산업 수혜주 |
| 삼성전자 | 코스피 | 고령화 사회(노인복지) |
| 삼성전자 | 코스피 | 의료기기 |
| 삼성전자 | 코스피 | 5G(5세대 이동통신) |
| 삼성전자 | 코스피 | 시스템반도체 |
| 삼성전자 | 코스피 | 뉴로모픽 반도체 |
| 삼성전자 | 코스피 | CXL(컴퓨트익스프레스링크) |
| 삼성전자 | 코스피 | 온디바이스 AI |
| 삼성전자 | 코스피 | 반도체 대표주(생산) |
| 삼성전자 | 코스피 | 3D 낸드(NAND) |
| 삼성전자 | 코스피 | SSD |
| 삼성전자 | 코스피 | HBM(고대역폭메모리) |
2024년 8월 29일 네이버 증권에서 제공하는 데이터 기준으로 무려 32개 종목의 테마를 가지고 있는 것을 알수 있었다. 이를 통해서, 하나의 종목은 여러개의 테마를 가질 수 있고, 전체 테마를 펼쳐서 시각화해 보면 그래프 처럼 보여줄 수 있겠다 라는 생각을 했다. (수집한 데이터를 활용한 데이터 시각화 까지 해볼 수 있겠다!)
프로젝트 1차 목표에 대한 프로세스는 간단하게 아래처럼 나타낼 수 있을 것 같다.
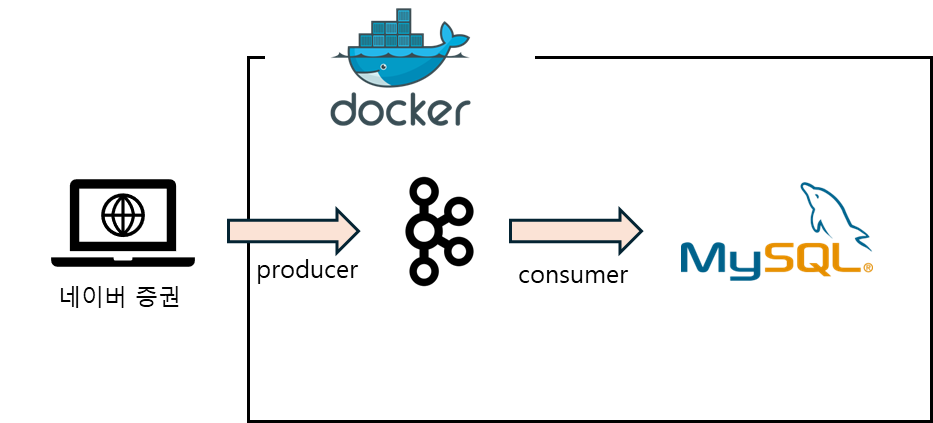
1. 데이터 수집
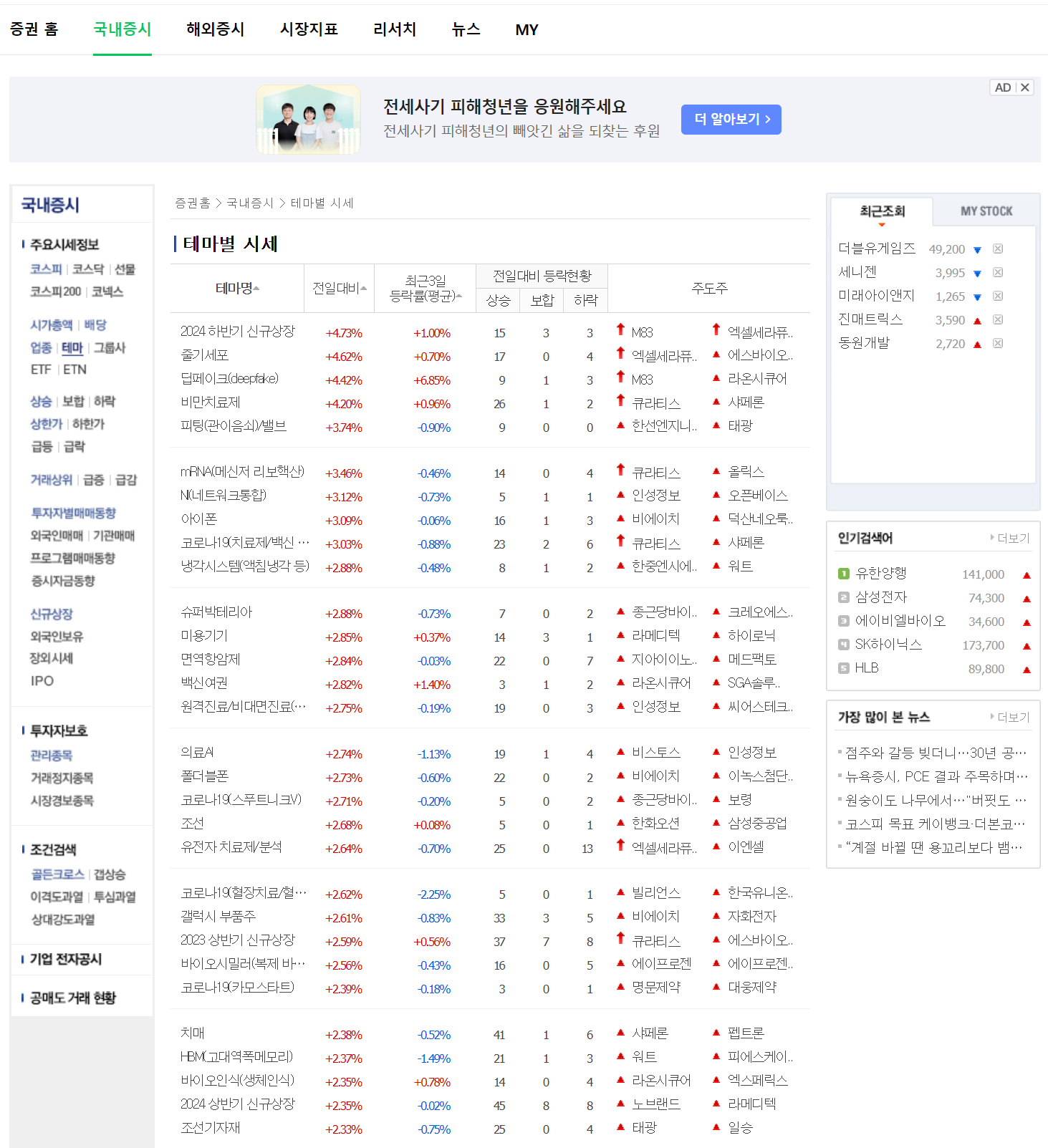
네이버 증권 홈 > 국내증시 > 테마 를 클릭하면 아래와 같은 화면이 나온다. (https://finance.naver.com/sise/theme.naver)
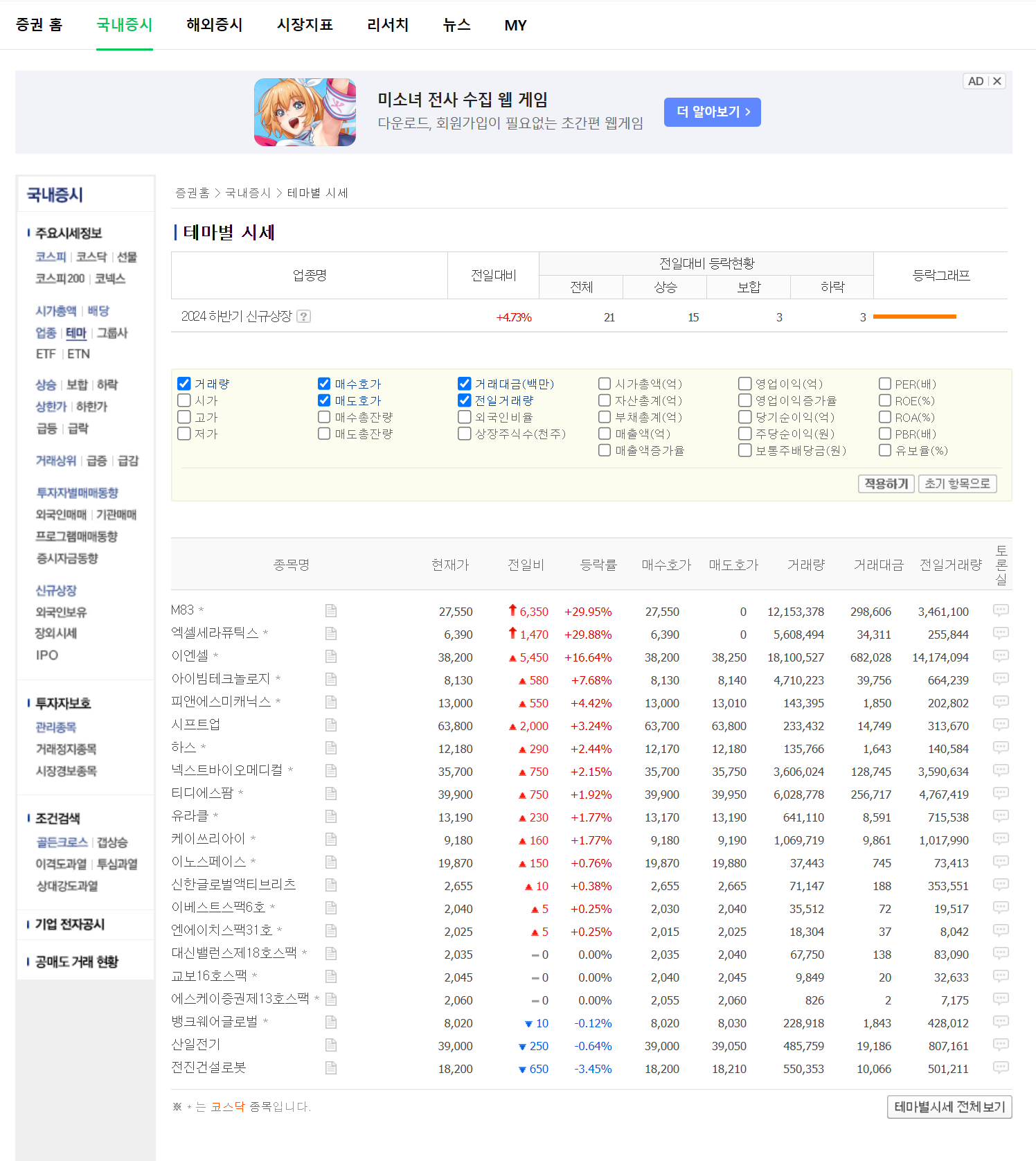
만약 2024 하반기 신규상장 을 클릭하면 해당 테마에 속한 종목들이 나오게 된다. (https://finance.naver.com/sise/sise_group_detail.naver?type=theme&no=562)
url을 잘 보면 뒤에 no=562 라고 되어 있는 부분이 해당 테마주의 id 라는 것을 알 수 있었다.
그래서 바로, 네이버 증권 데이터 수집을 하기 위해서 프로토타입 코드를 먼저 작성했다.
[프로토타입 데이터 수집 코드]
import requests
from bs4 import BeautifulSoup
import pandas as pd
import re
import time
url = "https://finance.naver.com/sise/theme.naver?&page=8"
response = requests.get(url)
rescode = response.status_code # 요청이 성공적으로 이루어졌는지 확인
# BeautifulSoup 객체 생성
soup = BeautifulSoup(response.text, "html.parser")
# 테마 리스트 테이블 찾기
table = soup.find("table", class_="type_1 theme")
data = []
rows = table.find_all("tr")
# print(rows)
for row in rows:
cols = row.find_all("td")
if len(cols) > 0 and cols[0].get_text(strip=True): # 데이터가 있는 행인지 확인
theme_name = cols[0].get_text(strip=True)
mtch = re.search(r'no=(\d+)', cols[0].find('a')['href'])
idx = mtch.group(1)
up_down = cols[1].get_text(strip=True)
change_rate = cols[2].get_text(strip=True)
data.append([theme_name, up_down, change_rate, idx])
# print(data)
# DataFrame으로 변환
df = pd.DataFrame(data, columns=["Theme", "Up/Down", "Change Rate", "idx"])
# 데이터 확인
df.head()
추후 해당 프로젝트 고도화(?)를 위해 리팩토링을 함께 진행하였다. 리팩토링은 디자인 패턴 중 템플릿 메소드 패턴을 적용하여 진행하였다.(GPT형님이 추천해줬음)
템플릿 메소드 패턴 (Template Method Pattern)
템플릿 메소드 패턴은 알고리즘의 구조를 정의하고, 서브클래스에서 알고리즘의 특정 단계를 재정의할 수 있도록 하는 디자인 패턴
[템플릿 메소드 패턴을 적용한 수집 코드]
추상 클래스(ThemeScraper)에 기본적인 웹 스크래핑 구조를 정의하고, 세부적인 부분은 서브클래스(NaverThemeScraper)에서 구현하도록 작성하였다.
import requests
from bs4 import BeautifulSoup
import pandas as pd
import re
import logging
from abc import ABC, abstractmethod
import time
import os
from datetime import datetime
logging.basicConfig(level=logging.INFO)
class ThemeScraper(ABC):
def __init__(self, base_url, start_page, end_page):
self.base_url = base_url
self.start_page = start_page
self.end_page = end_page
def scrape(self):
all_data = pd.DataFrame()
for page in range(self.start_page, self.end_page + 1):
logging.info(f"Fetching data from page {page}")
url = self.build_url(page)
html = self.fetch_html(url)
data = self.parse_html(html)
all_data = pd.concat([all_data, data], ignore_index=True)
return all_data
def build_url(self, page_number):
return f"{self.base_url}&page={page_number}"
def fetch_html(self, url):
response = requests.get(url)
if response.status_code != 200:
logging.error(f"Failed to fetch data from {url}")
raise Exception(f"Failed to fetch data from {url}")
return response.text
@abstractmethod
def parse_html(self, html):
pass
class NaverThemeScraper(ThemeScraper):
def parse_html(self, html):
soup = BeautifulSoup(html, "html.parser")
table = soup.find("table", class_="type_1 theme")
if table is None:
logging.error("Failed to find the theme table on the page.")
raise Exception("Failed to find the theme table on the page.")
data = []
rows = table.find_all("tr")
current_time = time.strftime('%Y-%m-%d %H:%M:%S')
for row in rows:
cols = row.find_all("td")
if len(cols) > 0 and cols[0].get_text(strip=True):
theme_name = cols[0].get_text(strip=True)
link_tag = cols[0].find('a')
mtch = re.search(r'no=(\d+)', link_tag['href']) if link_tag else None
idx = mtch.group(1) if mtch else None
up_down = cols[1].get_text(strip=True)
change_rate = cols[2].get_text(strip=True)
data.append([theme_name, up_down, change_rate, idx, current_time])
df = pd.DataFrame(data, columns=["ThemeName", "UpDown", "ChangeRate", "idx", "collectTime"])
return df'Toy Project' 카테고리의 다른 글
| [프로젝트명 : 미정] ETL 구축하기 - ③ Docker 환경 구축 (5) | 2024.09.02 |
|---|---|
| [프로젝트명 : 미정] ETL 구축하기 - ② 데이터 수집 (0) | 2024.09.02 |

