지난 포스팅에서는 네이버 증권 테마 데이터 수집 코드를 작성하고, 리팩토링 하는 부분까지 진행을 했다. 이번 포스팅에서는 세부 종목 데이터 수집하는 코드를 작성하는 내용까지 작성할 예정이다. 이전에 진행한 내용은 아래 링크를 통해서 확인할 수 있다.
2024.08.31 - [Toy Project] - [프로젝트명 : 미정] ETL 구축하기 - ①
[프로젝트명 : 미정] ETL 구축하기 - ①
프로젝트의 목표는 Docker 를 활용하여 카프카로 데이터를 수집하고 RDB에 저장하는 것이 1차 목표이다. Docker를 사용해 본적이 없었기 때문에 생활코딩(이고잉)님의 Docker 입문 수업을 듣고 시작하
ssanggo.tistory.com
1. 데이터 수집 (세부 종목)
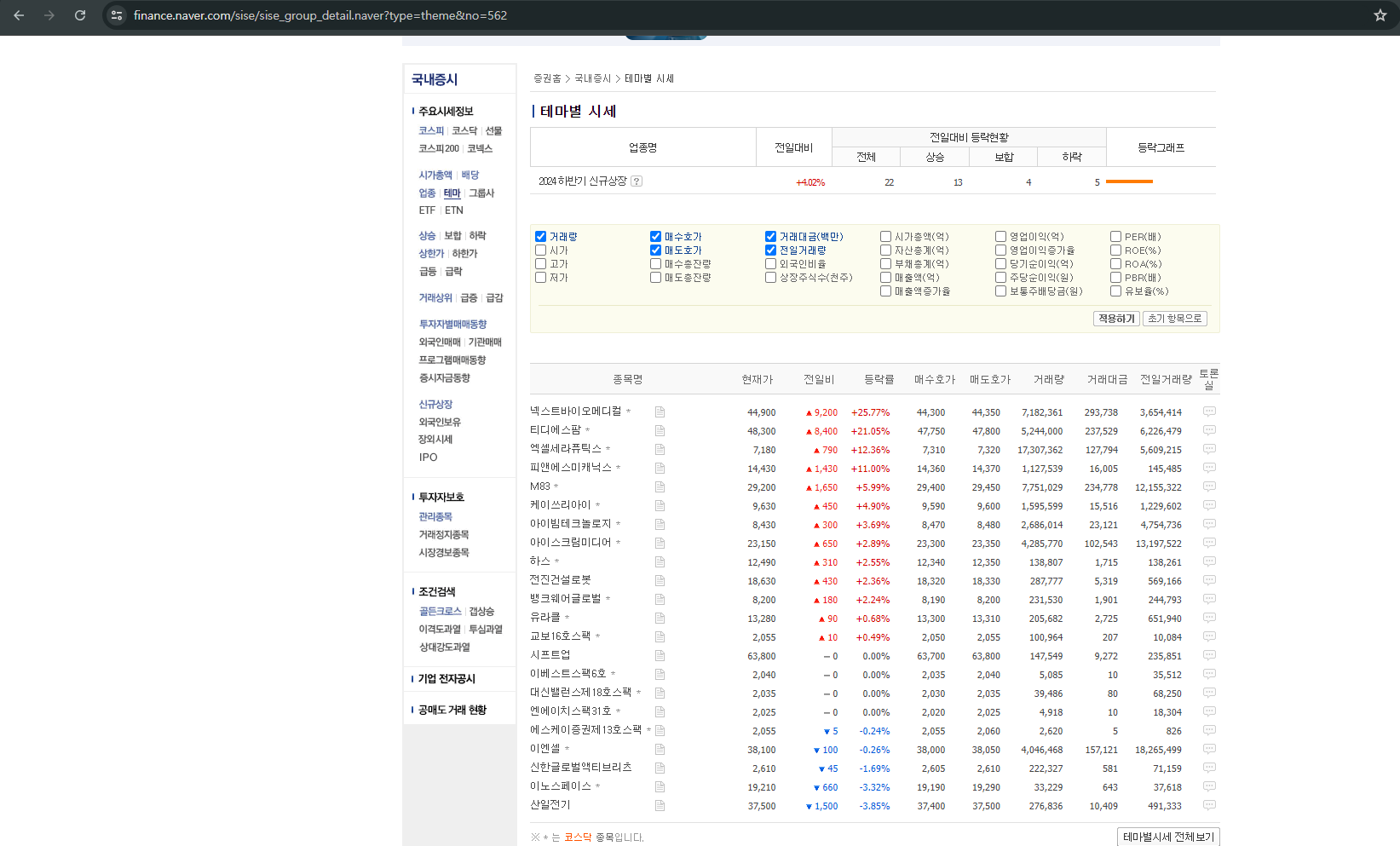
해당 테마주 안에 어떤 주식종목들이 있는지 스크래핑을 하기 위해서는 테마명에 있는 Link 를 타고 들어가면 확인할 수 있다. 예를 들어, 세부 종목은 테마명에 있는 "2024년 하반기 신규상장" 테마를 클릭하면 세부 종목 페이지로 변경된다. (이때 url 주소도 변경된다)
새로운 링크를 보면, 링크 뒤에 no=562 라고 되어 있는 부분을 확인할 수 있는데, 이는 네이버 증권에서 정의된 테마에 대한 고유 id인 것을 알 수 있었고, 테마명과 id 함께 텍스트 추출 후 변경된 url을 순회하면서 관련된 종목들을 수집할 예정이다.
https://finance.naver.com/sise/theme.naver?&page=1
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
https://finance.naver.com/sise/sise_group_detail.naver?type=theme&no=562
class NaverThemeDetailScraper(ThemeScraper):
def __init__(self, base_url, idx):
super().__init__(base_url, start_page=1, end_page=1)
self.idx = idx # idx를 저장
def scrape(self):
logging.info(f"Fetching data for idx {self.idx}") # idx로 로그 출력
# HTML 가져오기
url = self.build_url(1) # 페이지 1은 고정
html = self.fetch_html(url)
data = self.parse_html(html)
return data
def parse_html(self, html):
soup = BeautifulSoup(html, "html.parser")
table = soup.find("table", class_="type_5")
if table is None:
logging.error(f"Failed to find the detail table on the page.")
raise Exception("Failed to find the detail table on the page.")
data = []
rows = table.find_all("tr")
current_time = time.strftime('%Y-%m-%d %H:%M:%S') # 현재 시간
for row in rows:
cols = row.find_all("td")
if len(cols) > 0 and cols[0].get_text(strip=True):
stock_name = cols[0].get_text(strip=True)
# 코스피/코스닥 구분
market = "코스닥" if '*' in stock_name else "코스피"
stock_name = stock_name.replace('*', '').strip()
# "테마 편입 사유" 제거
inclusion_reason = cols[1].get_text(strip=True).replace("테마 편입 사유", "").strip()
current_price = cols[2].get_text(strip=True)
prev_day_diff = cols[3].get_text(strip=True)
change_rate = cols[4].get_text(strip=True)
buy_price = cols[5].get_text(strip=True)
sell_price = cols[6].get_text(strip=True)
volume = cols[7].get_text(strip=True)
trading_value = cols[8].get_text(strip=True)
prev_volume = cols[9].get_text(strip=True)
data.append([
stock_name, market, inclusion_reason, current_price,
prev_day_diff, change_rate, buy_price,
sell_price, volume, trading_value,
prev_volume, current_time, self.idx
])
# 데이터프레임 생성
df = pd.DataFrame(data, columns=[
"stockName", "marketType", "reason", "currentPrice", "prevDayDiff", "changeRate",
"buyPrice", "sellPrice", "volume", "tradingValue", "prevVolume", "currentTime", "idx"
])
return df해당 코드는 기존 데이터 수집코드에서와 같이 세부적인 부분을 서브클래스로 구현하도록 코드를 작성하였다.
데이터 수집 코드를 작성하면서 간단하게 데이터 전처리 할 수 있는 부분들은 데이터를 추출하면서 변환 및 추가하였다. 예를 들면, 세부 종목을 스크래핑 하면서 종목명에 "엑셀세라퓨틱스*" 과 같이 종목명 뒤에 *이 붙으면, 코스닥 종목이고, 안붙은 종목은 코스피 종목으로 분류가 되기 때문에 스크래핑할 때 항목을 추가하였다. 그리고 테마편입사유를 스크래핑을 하면 " 테마편입사유"가 앞에 계속 붙는 문제가 있어서 전처리를 하고 수집하도록 코드를 작성하였다.
'Toy Project' 카테고리의 다른 글
| [프로젝트명 : 미정] ETL 구축하기 - ③ Docker 환경 구축 (5) | 2024.09.02 |
|---|---|
| [프로젝트명 : 미정] ETL 구축하기 - ① 데이터 수집 (1) | 2024.08.31 |

